Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
简介
Native Sparse Attention 核心解决了长上下文资源利用多问题(在 64k 长上下文下,原始的 Attention 机制共享了推理的 70% - 80% 时延)。而存在的 Attention 机制有以下两个问题:
- 理论和实际不匹配,实际速度达不到理论速度。
- 只在推理阶段做优化,不考虑训练阶段(例如,在训练还是用的原 Attention 方案,在推理考虑做压缩)
基于以上考量,提出协同硬件以及原生可训练的稀疏形Attention机制。
算法设计
其算法如图,这里不贴公式了(基本属于大道至简,有个公式没看明白不知道是不是写错了,下文按照我的理解复述)
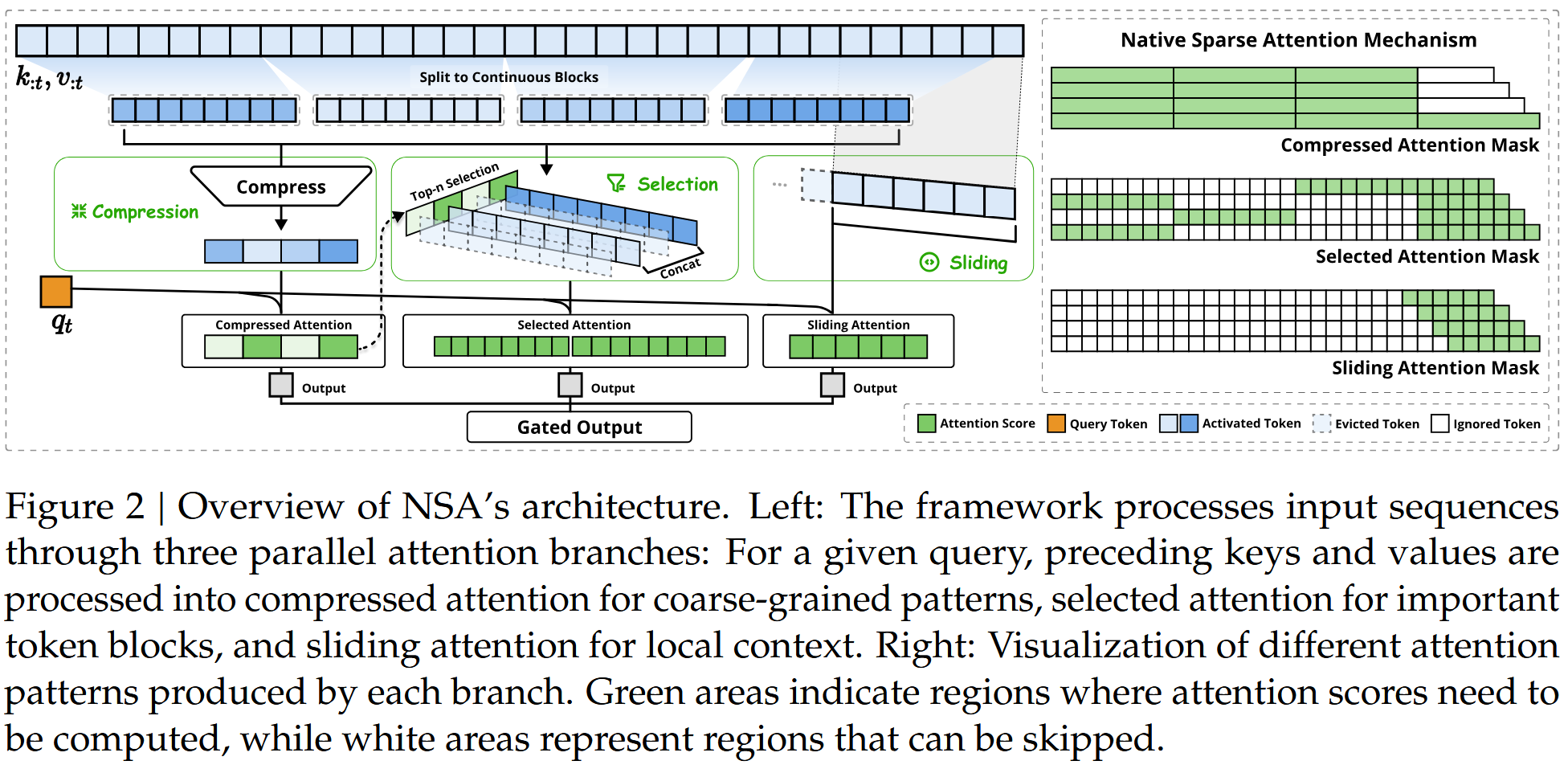
KV-Cache 如果非常长自然而然能想到几种"压缩"方式:
- Compression:直接压缩,为了匹配硬件,按块压缩是最有性价比的。如图的将 KV-Cache 中的 tokens 分块,然后直接套一个 MLP 层输出压缩值,用压缩后的 KV-Cache 做 Attention 计算。直觉解释:上下文中的信息是可以压缩到简单的表示,比如有些废话可以总结起来用一句话来说明,这个和以前做 RAG 这种差不多,把上下文分段做个总结,只是放到了模型层去。
- Selection:选重要的 token,压缩后的数据粒度太粗糙了,选几个重要的出来用他们的全部 tokens(具体选直接用了之前 Compression 的块计算的分数做个排序)。直觉解释:还是之前那个场景,总结后的文本可能丢失了细节,这个时候要把最重要的几个原文本取出来。
- Sliding:最近的上下文不要压缩了,还是使用原始的 tokens。直觉解释:最近的对话不能用压缩后的数据,就和聊天一样,最近几条数据要保留原始的,要不然你总结后丢失信息太多了。
拿到上述三个计算后,加一个门控,把他们三个结果加起来,得到最后输出。
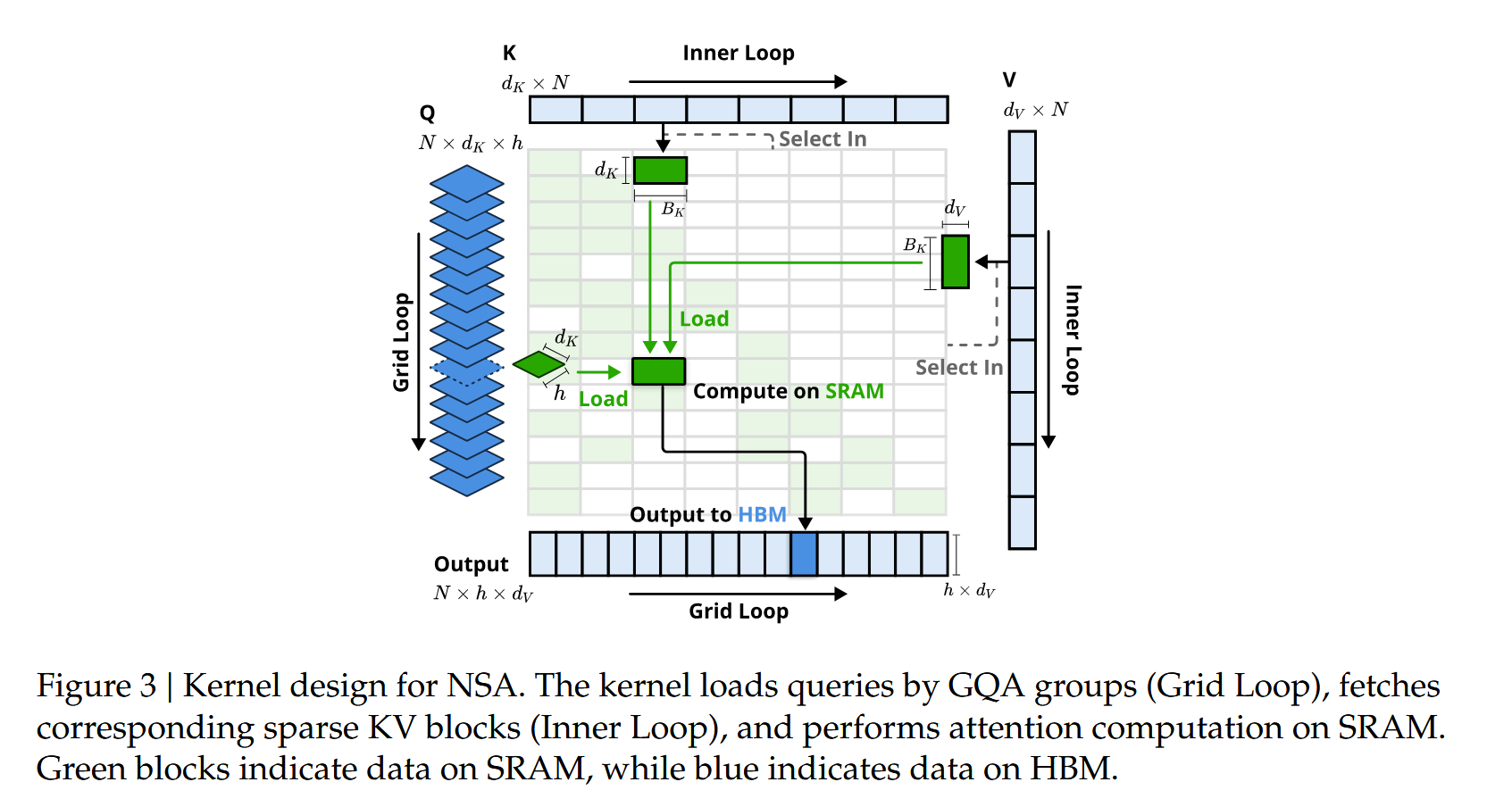
硬件设计
内核设计基本保持和 FlashAttn 一致,只是 FlashAttn 的实现是取连续的 KV-Cache, 他们提的 NSA 取部分 KV-Cache。
然后文章提到他们用 triton 去实现的。